논문 : https://openaccess.thecvf.com/content_CVPR_2019/html/Kim_Deep_Video_Inpainting_CVPR_2019_paper.html
CVPR 2019 Open Access Repository
Dahun Kim, Sanghyun Woo, Joon-Young Lee, In So Kweon; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5792-5801 Video inpainting aims to fill spatio-temporal holes with plausible content in a video. Despi
openaccess.thecvf.com
Deep Video Inpainting 논문 리뷰
초록 :
Video Inpainting은 시공간 구멍을 비디오에서 그럴듯한 내용으로 채우는 것을 목표로한다.
Image Inpainting을 위한 Deep neural network(DNN)의 엄청난 발전에도 불고하고, 추가적인 시간 차원 떄문에 이러한 방법을 비디오 범위로 확장하기는 어렵다.
이 연구에서, 우린 빠른 Video Inpainting을 위한 새로운 DNN 구조를 제안한다.
이미지 기반으로 Encoder-Decoder 모델을 기반으로 한 우리의 프레임워크는 이웃 프레임에서 정보를 수집하고 정제하고 구멍을 합성하도록 설계되어있다.
동시에, 출력은 정기적인 피드백과 시간의 메모리 모듈에 의해 시간적으로 일관되도록 실시된다.
최첨단 Image Inpainting 알고리즘과 비교할 때, 우리의 방법은 의미적으로 훨씬 정확하고 시간적으로 매끄러운 비디오를 생성한다.
시간이 많이 걸리는 최적화 방식에 의존하는 이전의 비디오 완성 방법과 달리, 우리의 방법은 경쟁력 있는 비디오 결과를 생성하면서 거의 실시간으로 실행된다.
마지막으로, 우리는 우리의 프레임워크를 비디오 리타겟팅 작업에 적용하여 시각적으로 만족스러운 결과를 얻었다.
논문에서는 Image Inpainting에 시간의 차원을 추가해 이미지간의 연관성을 확보하는 것, 학습 및 적용하는데 걸리는 시간을 줄이는걸 목표로 한다.
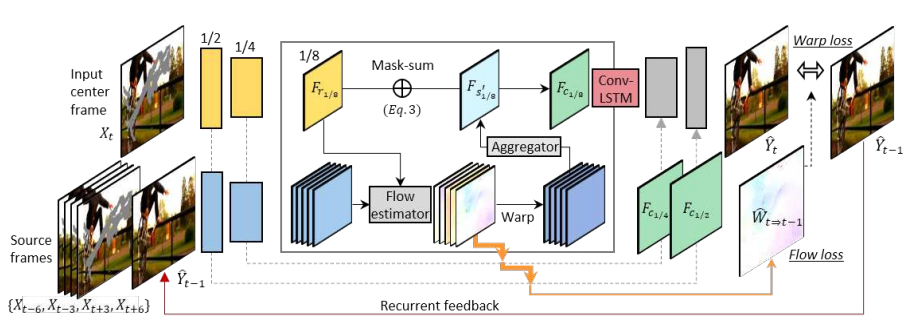
1. 순차적인 다중-단일 프레임 인페인팅 작업으로 비디오 인페인팅을 캐스팅하고 새로운 심층 3D-2D 인코더-디코더 네트워크를 제시한다. 우리의 방법은 이웃 프레임에서 특징을 효과적으로 수집하고 이를 기반으로 누락된 콘텐츠를 합성한다.
2. 우리는 시간적 안정성을 위해 순환 피드백과 기억 계층을 사용한다. 효과적인 네트워크 설계와 함께 흐름 손실과 뒤틀림 손실이라는 두 가지 손실을 통해 강력한 시간적 일관성을 구현한다.
3. 우리가 아는 한, 그것은 일반적인 비디오 페인팅 작업을 위한 단일 통합 딥 네트워크를 제공하는 최초의 작업이다. 우리는 광범위한 주관적이고 객관적인 평가를 수행하고 그 효능을 보여준다. 또한 비디오 리타겟팅 및 초해상도 작업에 우리의 방법을 적용하여 유리한 결과를 입증한다.